Все публикации
Новости компании и материалы блога в едином хронологическом потоке.
-

Компании Picodata и Directum подтвердили совместимость продуктов
Интеграция супераппа Directum Omni и распределенной СУБД для критической инфраструктуры Picodata Radix гарантирует стабильную и безопасную работу в корпоративном суперприложении. Тестирование проводилось в условиях, приближенных к реальной эксплуатации, с одновременной работой десятков активных пользователей супераппа Directum Omni. Проверка ошибок не выявила, интеграция показала стабильное и корректное подключение в кластерной конфигурации.
-

Нагрузочное тестирование YCSB: Sirin vs Apache Cassandra
-

Релиз Sirin 1.3.0
Команда разработчиков Picodata рада сообщить о выпуске Sirin 1.3.0 — коммерческого плагина к Picodata, реализующего поддержку поддержку API Apache Cassandra (CQL и протокол Cassandra v4). Новая версия плагина работает с Picodata 26.1.3 или новее и содержит новую функциональность и улучшения производительности.
-
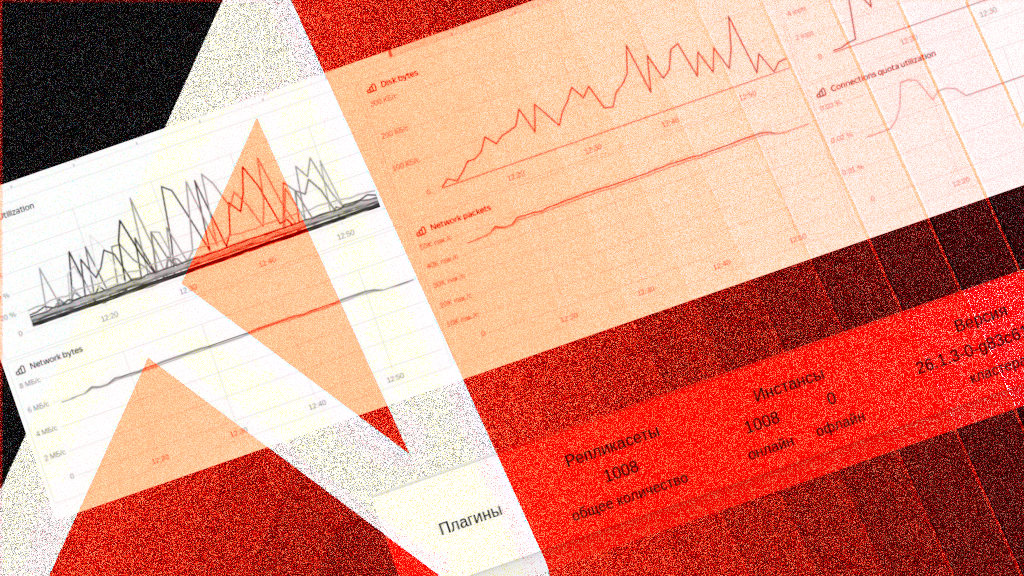
Протестированы кластеры Picodata из 1000+ узлов
Специалисты компании Picodata проверили производительность Ansible-роли и замерили время развёртывания масштабного кластера СУБД в условиях, приближённых к промышленным
-

Нагрузочное тестирование LWT: Sirin vs Apache Cassandra
-

Подтверждена совместимость Picodata с AggreGate
Picodata и Aggregate успешно завершили цикл испытаний распределённой СУБД Picodata вместе с платформой Tibbo Aggregate.
-

Вышла новая версия Radix 1.0.0 на основе Picodata 26.1.2
Команда разработчиков Picodata рада сообщить о свежем релизе плагина Radix 1.0.0 на основе Picodata 26.1.2. Это первый LTS-релиз Radix.
-

Нагрузочное тестирование плагина Sirin для СУБД Picodata
-

Релиз Sirin 1.2.0
Команда разработчиков Picodata рада сообщить о выпуске Sirin 1.1.0 — коммерческого плагина к Picodata, реализующего поддержку поддержку API Apache Cassandra (CQL и протокол Cassandra v4). Новая версия плагина работает с Picodata 25.5.1 или новее и содержит новую функциональность и улучшения производительности.